
Hi! I’m Mallory Johnson, an Evaluation Specialist with the UC Davis Schools of Health Evaluation Unit. Have you been frustrated by webpages that allow you to view data in a browser, but don’t have export or download functions? Government websites in particular often post useful evaluation information in useless formats. After all, that table is no help to your evaluation efforts stuck on a computer screen. Data scraping (or screen scraping) allows you to extract data from constrictive webpages, kind of like scratching delicious frosting off a stale cake. Here are time-saving techniques for scraping data off the internet into Excel or CSV files.
Rad Resource: Google Spreadsheets is a free resource that allows you to import HTML tables into a spreadsheet.
1. Open a Google Spreadsheet:
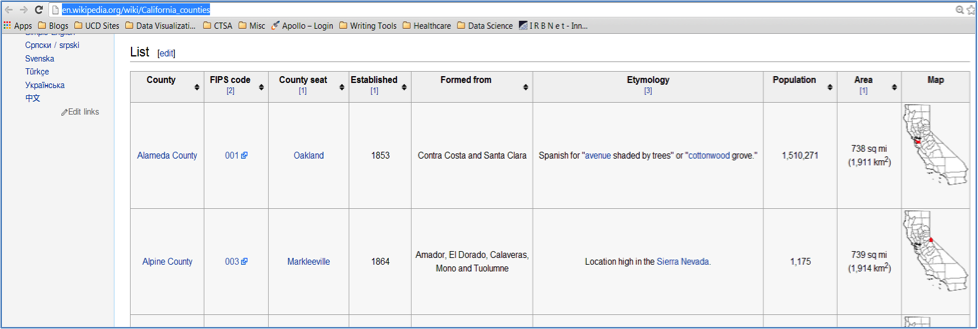
2. Locate the URL from the webpage you would like to scrape:
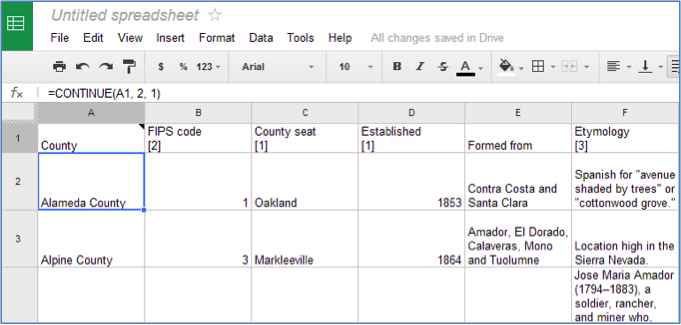
3. Enter the following formula into the first cell..
Formula: =importHTML(“websiteURL”,“table”,“# of table on the webpage”)
Example: =importHTML(“http://en.wikipedia.org/wiki/California_counties”,”table”,2)
Hot Tip: It may take some trial and error to locate the correct table number (the last portion of the formula). Review the HTML source code for difficult cases. For Internet Explorer users, navigate to the page, select “view” from the toolbar, and click “source”. Then, count the number of times you see the word “table” in the source-code. This will give you the number of tables within the webpage.
4. Press enter, and data will magically populate the spreadsheet. Data can be exported as Excel, CSV, or text files.
Rad Resource: Import.io (http://import.io/) is a new product that allows users to create data scrapers, spiders, and bots with an easy to use “drag and drop” interface. The software is still in beta, but it promises to be a coding-free solution for the programming-challenged.
Rad Resource: Beautiful Soup is a Python library designed to make screen scraping projects faster than writing code from scratch. For those with rudimentary programming knowledge, Beautiful Soup is a scraping, parsing, url-finding wonder. Both Beautiful Soup and Python are open-source. Tutorials are available from multiple free venues, such as Coursera and Code Academy.
Lessons Learned: Just because data is “scrape-able” doesn’t mean it’s legal to possess it. Traditional copyright and privacy protection rules apply. Also, these techniques should be avoided on password protected websites– even when users utilize avatars or usernames to protect their identities (programs exist with the capability to decode them, making personal information frighteningly transparent). Most producers of web-based media monitor their websites for scraping activity. If you wouldn’t want site-owners or users to know that you scraped their data, chances are that you shouldn’t.
Do you have questions, concerns, kudos, or content to extend this aea365 contribution? Please add them in the comments section for this post on the aea365 webpage so that we may enrich our community of practice. Would you like to submit an aea365 Tip? Please send a note of interest to aea365@eval.org . aea365 is sponsored by the American Evaluation Association and provides a Tip-a-Day by and for evaluators.
Wow, I never knew you could do that in Google Docs. If you do happen to find a JSON feed, a good technique is to just paste the JSON url into json-csv.com and it will produce a nice CSV spreadsheet.