
Hi! My name is Katie Paschall and I am a doctoral candidate in Family Studies and Human Development at the University of Arizona. The AEA365 blog is a great space to learn about relevant statistical tools, so I wanted to weigh on in the utility of cluster analysis for evaluation research. Cluster analyses help you identify meaningful, distinct subgroups in your sample, and you may even find that you can compare the subgroups to other studies!
Perhaps you are evaluating a program aimed improving the quality of maternal parenting, and you wonder if there are subgroups of mothers who are more or less responsive to your program. You could look at moderators of effectiveness one by one, finding that those within a lower socioeconomic bracket, single, and/or depressed were the least likely to improve their parenting behaviors. This would be a variable-centered approach. But perhaps there are unique combinations of demographic risks that differentially predict program effectiveness. Identifying these combinations, or subgroups, means you could meaningfully focus efforts for future programming. To identify these unique subgroups and link them to outcomes, you could use a cluster analysis.
Hot tip: If you have too many characteristics that define your clusters, it will be difficult to detect a manageable amount of meaningful subgroups (there are no firm rules, but it’s not common to see more than 10). Most clusters are comprised of one family of characteristics (economic hardship, delinquent behaviors, psychiatric symptoms, etc.).
Lesson learned: Check the literature for previous person-centered analyses, but be prepared to be a pioneer! Hypotheses are not typical in this line of research. Unless others have conducted cluster analyses with your same population, all you can hypothesize is that distinct subgroups exist within your sample. The choice of how many clusters exist in your sample is a mostly data-driven question – look at a dendogram to see how the data is clustering. See how the clusters differ on the characteristics that comprise them (use an ANOVA!), and then pick the best number of clusters based on conceptual and theoretical soundness.
Cool trick: The most intuitive way to plot your clusters is with a line graph.
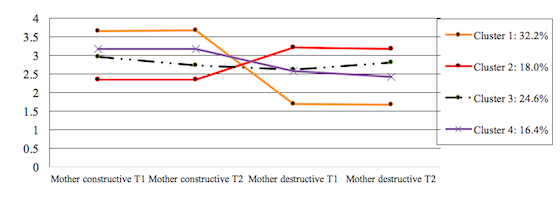
Figure 1. Clusters of maternal perceptions of conflict at two time points.
Once you have the clusters, you see how they differ by other covariates, and how they differentially predict outcomes. From here, you can add moderating and mediating effects.
Lesson learned: Identifying subgroups can help you learn what combinations are most noteworthy. Clinicians often rely on cumulative risk indexes to understand who is most at risk for experiencing a particular outcome; cluster analyses can help elucidate important combinations of risks that are salient to a particular outcome. Keep your eye on implications for future replication studies as well as clinical implications. Happy clustering!
Do you have questions, concerns, kudos, or content to extend this aea365 contribution? Please add them in the comments section for this post on the aea365 webpage so that we may enrich our community of practice. Would you like to submit an aea365 Tip? Please send a note of interest to aea365@eval.org . aea365 is sponsored by the American Evaluation Association and provides a Tip-a-Day by and for evaluators.
This can be a very valuable approach for program evaluation because we often can identify outcome variations based on group distinctions quite often. I used a similar approach evaluating welfare reform in the early 2000’s and discovered groups needed very different interventions–and some should have been another program better fitted to their needs. It helps tailor recommendations for greater effectiveness.
Thanks for sharing.
I think this topic would be perfect for an AEA Coffee Break webinar!
I agree!